Cultural Dynamics
The study of how cultural items become popular, how misinformation spreads in social networks, and how shared interpretations evolve over time greatly benefits from a “computational turn” in sociology. Networked digital trace data, archives of digitized text, and the computational tools for their analysis help to address some of our discipline’s core questions in novel ways.
“Wide Social Influence and the Emergence of the Unexpected: An Empirical Test Using Spotify Data. Sociological Science 12:715-742.

This article integrates digital trace data, topic modeling, and agent-based simulations to investigate how social influence shapes collective outcomes. It exemplifies how computational methods and sociological theories can be rigorously combined to address fundamental questions in the discipline. It demonstrates that under certain conditions, social influence can decouple what people do from what they initially preferred. Looking at more than a million Spotify users, we show the importance of partial taste overlap between senders and receivers of influence: with too little similarity there is no influence, with too much no novelty. “Wide” social influence hits the sweet spot, such that adoptions outside people’s usual repertoires become likely. Success and inequality in cultural markets are not solely driven by intrinsic quality or simple popularity cascades. Instead, the width of influence—how peers expose and make novel options acceptable—contributes to surprising collective outcomes and cultural change.
“Estimating Social Influence Using Machine Learning and Digital Trace Data.” Pp. 673-696 in The Oxford Handbook of the Sociology of Machine Learning, 2025.
 Applying machine learning to digital trace data—including text data—can improve estimates of social influence effects. Estimating social influence effects is challenging outside experimental settings because people form relationships partly based on unobserved, homophilous preferences. Sophisticated algorithms take advantage of the high temporal and contextual granularity of digital trace data to account for various sources of confounding. Valid estimation of peer effects improves our understanding of how macro-phenomena emerge from social interdependencies, network effects, and critical masses.
Applying machine learning to digital trace data—including text data—can improve estimates of social influence effects. Estimating social influence effects is challenging outside experimental settings because people form relationships partly based on unobserved, homophilous preferences. Sophisticated algorithms take advantage of the high temporal and contextual granularity of digital trace data to account for various sources of confounding. Valid estimation of peer effects improves our understanding of how macro-phenomena emerge from social interdependencies, network effects, and critical masses.
“Seeded Topic Models in Digital Archives: Analyzing Interpretations of Immigration in Swedish Newspapers, 1945–2019.” Sociological Methods and Research 55(1):120-156.
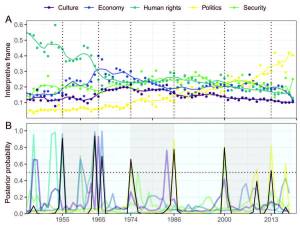 Sociologists are discussing the need for more formal ways to extract meaning from text. The semi-supervised seeded topic model allows sociological knowledge to be infused into the computational learning of meaning structures. We extract measures of shared interpretations of immigration from a vast corpus of millions of Swedish newspaper articles from the period 1945–2019. We infer turning points that partition discourse into meaningful eras and locate Sweden’s era of multicultural ideals that coined its tolerant reputation.
Sociologists are discussing the need for more formal ways to extract meaning from text. The semi-supervised seeded topic model allows sociological knowledge to be infused into the computational learning of meaning structures. We extract measures of shared interpretations of immigration from a vast corpus of millions of Swedish newspaper articles from the period 1945–2019. We infer turning points that partition discourse into meaningful eras and locate Sweden’s era of multicultural ideals that coined its tolerant reputation.
“Computational Text Analysis for Building and Testing Social Theory” Kölner Zeitschrift für Soziologie und Sozialpsychologie, 2026.
Speaking to both “thick description” and “causal inference,” this article describes how computational text analysis is commonly used and might be used by sociologists in the future, bridging quantitative scale with qualitative depth, and revitalizing interpretive approaches in sociology.
this article describes how computational text analysis is commonly used and might be used by sociologists in the future, bridging quantitative scale with qualitative depth, and revitalizing interpretive approaches in sociology.
“Network Segregation and the Propagation of Misinformation.” Scientific Reports 13(1):917.
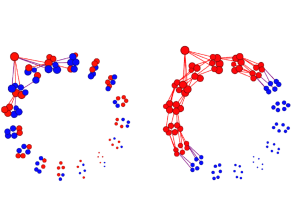 How do ideologically segregated networks impact the spread of misinformation? We created 16 independent online ecosystems in which participants could share true and false messages about society, science, and politics. We recruited US participants, varying the experimental network architecture from integrated (50:50 liberals and conservatives) to segregated echo chambers. Partisan sorting systematically undermines the veracity of information circulating. Agent-based simulations models generalize this finding to different network topologies.
How do ideologically segregated networks impact the spread of misinformation? We created 16 independent online ecosystems in which participants could share true and false messages about society, science, and politics. We recruited US participants, varying the experimental network architecture from integrated (50:50 liberals and conservatives) to segregated echo chambers. Partisan sorting systematically undermines the veracity of information circulating. Agent-based simulations models generalize this finding to different network topologies.
“Partisan Belief in New Misinformation is Resistant to Accuracy Incentives.” PNAS Nexus 3(11):pgae506.
 Liberals and conservatives disagree on basic facts and regularly misgauge the accuracy of politicized information. Is this because they hold fundamentally different beliefs or are they just pretending? We study how experimental participants rate the veracity of new messages they never saw before, in the presence or absence of a monetary incentive for accuracy. Ideological differences in beliefs cannot be fully eliminated by incentives and hamper individuals’ ability to identify true from false content. Much belief in misinformation is sincere and thus immune to policy measures that increase accountability. The misinformation policy challenge is therefore not only one of inducing good behavior but also one of correcting false beliefs.
Liberals and conservatives disagree on basic facts and regularly misgauge the accuracy of politicized information. Is this because they hold fundamentally different beliefs or are they just pretending? We study how experimental participants rate the veracity of new messages they never saw before, in the presence or absence of a monetary incentive for accuracy. Ideological differences in beliefs cannot be fully eliminated by incentives and hamper individuals’ ability to identify true from false content. Much belief in misinformation is sincere and thus immune to policy measures that increase accountability. The misinformation policy challenge is therefore not only one of inducing good behavior but also one of correcting false beliefs.
“Analytical Sociology and Computational Social Science.” Journal of Computational Social Science 1(1):3-14.
![]() Analytical sociology (AS) focuses on social interactions among individuals and the hard-to-predict aggregate outcomes they bring about. It seeks to identify generalizable mechanisms giving rise to emergent properties of social systems which, in turn, feed back on individual decision-making. This research program benefits from computational tools (e.g. agent-based simulations, machine learning, large-scale web experiments), and has considerable overlap with the nascent field of computational social science (CSS). We outline how the theory-grounded approach of AS can help to move the field forward from mere descriptions and predictions to the explanation of social phenomena.
Analytical sociology (AS) focuses on social interactions among individuals and the hard-to-predict aggregate outcomes they bring about. It seeks to identify generalizable mechanisms giving rise to emergent properties of social systems which, in turn, feed back on individual decision-making. This research program benefits from computational tools (e.g. agent-based simulations, machine learning, large-scale web experiments), and has considerable overlap with the nascent field of computational social science (CSS). We outline how the theory-grounded approach of AS can help to move the field forward from mere descriptions and predictions to the explanation of social phenomena.
“Success in Cultural Markets: The Mediating Role of Familiarity, Peers, and Experts.” Poetics 51:17-36.
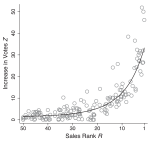
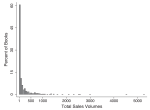
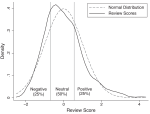
This article emphasizes the uncertainty of cultural markets and the relevance of social valuation in disseminating new releases. I hypothesize that recipients of culture simplify cultural choice by reacting to easily attainable signals of product value. Sales data from the German book industry (2001–2006) show that, in the highly ambiguous newcomer segment, imitation and negative media steer audience attention, at times leading to unintended aggregate outcomes, i.e. ‘bad’ bestsellers. This paper received the Karl-Polanyi-Award in 2016.
“Is Category Spanning Truly Disadvantageous? New Evidence from Primary and Secondary Movie Markets.” Social Forces 96(1):449–479.
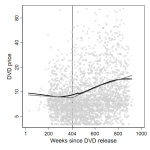
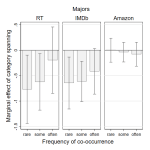
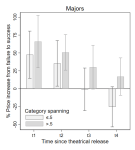
Genre assignments help audiences make sense of new releases. Releases that span categories are harder to place and thus shunned by their audiences—so the theory goes. We disentangle two mechanisms—reduced niche fitness and audience confusion—causing devaluation of category-spanning offers. Our data on 2,971 Hollywood movies show that negative spanning effects are far from universal, manifesting only if (a) combined genres are culturally distant, (b) products are released to a stable and highly institutionalized market context, and (c) offers lack familiarity as an alternative source of market recognition. This study modifies some widely acknowledged truisms regarding boundary crossing in cultural markets.
“Crowd Wisdom Relies on Agents’ Ability in Small Groups with a Voting Aggregation Rule.” Management Science 63(3):818–828.
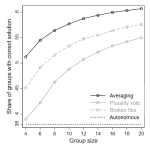
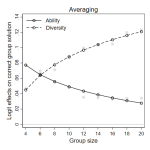
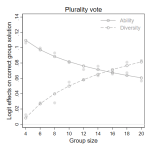
“Crowd wisdom” relies on the aggregation of independent judgments, and group accuracy rises with the number, ability, and diversity of its members. The mechanics of crowd wisdom are well understood for continuous estimation tasks (averaging). Much less so for discrete choice tasks (voting). While diversity is key when averaging individual estimates into accurate group judgments, accurate voting is much more dependent on individual ability. Decisions on optimal group composition (diversity vs. ability) hence strongly depend on the predictive situation (estimation vs. choice) at hand.
“Social Influence Strengthens Crowd Wisdom Under Voting.” Advances in Complex Systems 21(6):1850013.
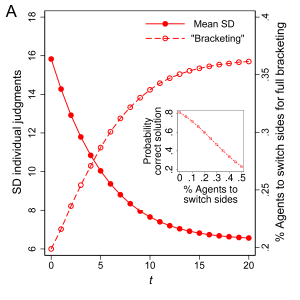 When people vote, social influence contributes to information aggregation and strengthens collective accuracy. This result stands in stark contrast to previously reported detrimental social influence effects in groups that average—i.e., use a social decision function we rarely encounter in real-world settings. The type of agent-based simulation reported on in this paper hold important ramifications for the design of collective decision-making in public administration and private firms
When people vote, social influence contributes to information aggregation and strengthens collective accuracy. This result stands in stark contrast to previously reported detrimental social influence effects in groups that average—i.e., use a social decision function we rarely encounter in real-world settings. The type of agent-based simulation reported on in this paper hold important ramifications for the design of collective decision-making in public administration and private firms
